

Uncovering hidden relationships in data to build an industry intelligence database
Overview
A think tank within China’s prestigious Nankai University has been manually tracking and building China’s only comprehensive database detailing the development of the country’s Artificial Intelligence (AI) industry. The think tank sought to expand its research coverage, and turned to Arboretica for its expertise in natural language processing (NLP) and automation.
The Challenge
For the past five years, a think tank within China’s Nankai University has been tracking the development of China’s Artificial Intelligence industry and building the country’s only comprehensive database about it.
In that time, the think tank relied heavily upon manual research to identify relationships between companies, and focused its research efforts primarily on Chinese companies and on data sources available only in simplified Chinese.
As the Nankai think tank sought to expand its research coverage, it turned to Arboretica. The think tank tasked Arboretica, known for expertise in natural language processing (NLP) and automation, with automating the build-out of the Chinese AI industry knowledge base:
- Taking the collection of data from a single region to global sources;
- Enabling automated identification of industry relationships; and
- Optimizing the structure and expansion of the database itself.
Arboretica was well-prepared for the challenge.
The Solution
Approach
Arboretica’s first order of business was to design a relationship-mapping process using NLP algorithms to replace the tedious manual tasks the think tank’s researchers had previously been using. The relationship mapping process was three-fold:
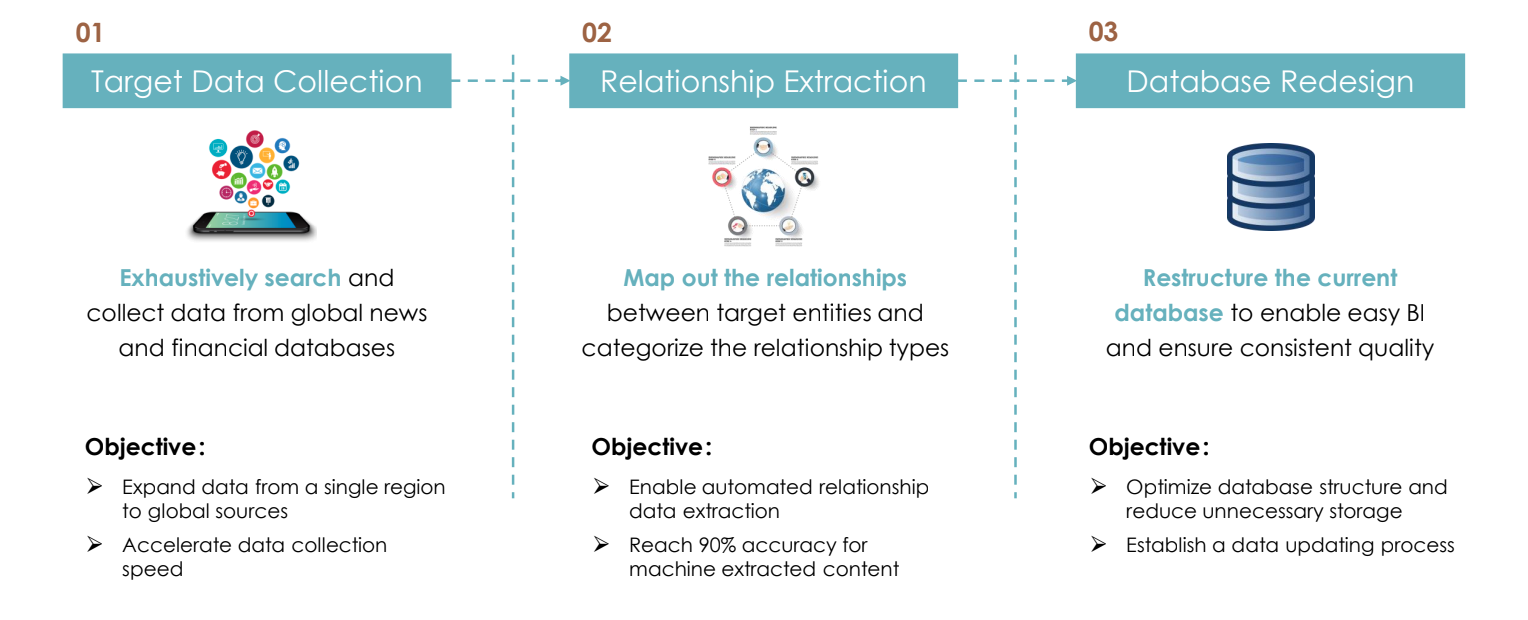
Step 1: Target Data Collection
Exhaustively search and collect data from global news and financial databases, expanding the reach of research beyond just a single a region and accelerating the data collection speed
Step 2: Relationship Extraction
Map out the relationships between target entities and categorize the relationship types, with the goals of not just enabling automated data relationship extraction but doing so at a 90% accuracy threshold or greater
Step 3: Database Redesign
Restructure the current database to enable easy business intelligence, ensure consistent quality, reduce unnecessary storage, and establish a data updating process
Implementation
Step 1: Target Data Collection
Through its manual efforts, the think tank had collected approximately 9,000 news articles from over 1,000 media in simplified Chinese only. Powered by Arboretica’s algorithms, the scope of the data collection grew extensively and rapidly to include 7x more articles than gathered through manual efforts:
- 12,000+ articles in English, French, and German languages from 550+ Western media sources
- 35,000+ articles in simplified and traditional Chinese from 700+ Chinese media
Step 2: Relationship Extraction
With the data collection underway, Arboretica began the process of relationship extraction. This was achieved with 2 crucial steps:
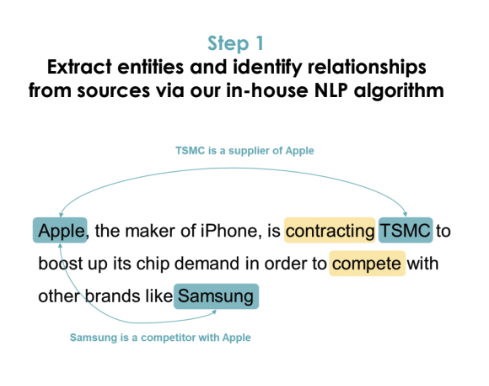
First, we scanned news articles and utilized our proprietary NLP process to extract relationships between entities. Our process, which includes Named Entity Recognition (NER) and a custom-built algorithm, can identify multiple types of relationships between entities by understanding the grammatical structure between sentences.

Second, we developed a network map, which visualizes the relationships and dependencies discovered in the first step, revealing both the influencers in the industry and the companies with a big potential for development.
Step 3: Database Redesign
With steps 1 and 2 complete, Arboretica was able to redesign the think tank’s database in a way that would allow for future growth.
The Results
The Nankai-based think tank now had more data and more accurate information at its fingertips than ever before. It also had a framework for data collection and a proven process for relationship extraction and database maintenance that could be relied upon for its efforts moving forward.
But perhaps most importantly, with Arboretica’s work, the think tank had demonstrated that utilizing algorithm-driven relationship mapping in conjunction with manual validation had significant, quantifiable advantages over traditional, manual-only methods of data collection and relationship mapping:
- A 150x increase in data coverage, from 20 sources collected per week in one language to 23,000 sources collected per week across four languages
- A 10x increase in data analysis speed, from approximately 200 words per minutes analyzed to approximately 2,000 words per minute analyzed
To learn how we could help you conduct an industry analysis, contact us.
